Listen to this AI-generated podcast summarizing the article content for easier digestion
1. Introduction
Traditional web scraping is dead. Imagine spending weeks setting up a system to collect data from the web for your business. Then, the website structure changes, and suddenly your data collection stops working. This is a common challenge everyone faces who collects data from the web - unless you're using AI.
In this comprehensive guide, I'll show you how I solved this headache and built an AI-powered scraping dashboard that continues working even when websites completely redesign their pages. No code changes needed. That's the power of combining traditional scraping with AI.
By the end of this article, you'll understand:
How to scrape with AI
How to save money on tokens
How to build a complete dashboard for managing your scraping operations
To demonstrate these concepts, I'll compare six different approaches using two test cases:
A job board that can be easily scraped without being blocked
A real estate listing site from Argentina with anti-bot measures
2. The Problems with Traditional Web Scraping
Let's start with Beautiful Soup, probably the most popular scraping tool around. Beautiful Soup is typically used in combination with the requests package. Here's what you need to know about this traditional approach:
Components and Costs
Tools: Beautiful Soup and requests (both open-source Python packages)
Basic Operation: Downloads entire HTML of a website
Features: Provides CSS selectors, filters, and modifiers for data extraction
Cost Structure: Base tools: Free. Additional costs: LLM costs for AI data extraction and proxy servers (depending on website requirements)
The Proxy Server Challenge
A key component often needed in traditional scraping is a proxy server. Here's why:
Acts as an intermediary for sending requests
Helps appear more human-like
Enables IP address rotation
Allows country-specific IP usage
Prevents blocking from target websites
Basic Beautiful Soup Implementation
Let me show you how traditional scraping works. First, you inspect the HTML and find selectors for the data you want to scrape. Here's a basic Python script using requests and Beautiful Soup:
1import requests
2from bs4 import BeautifulSoup
3
4defscrape_jobs():
5# Define the URL to scrape
6 url ="<https://example-job-board.com>"
7
8# Define headers to mimic human behavior
9 headers ={
10"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36"
When using this traditional approach with AI, you face a significant challenge: token costs. Let's break down the numbers:
A typical HTML file from our test case contains about 2,700 lines of code
When converted to tokens for AI processing, this equals over 65,000 tokens
You pay for both input and output tokens when using language models
This makes processing raw HTML extremely expensive at scale
This leads us to our first major insight: we need a more efficient way to prepare web data for AI processing. In the next section, we'll explore AI-powered scraping tools that solve these challenges while significantly reducing costs.
3. AI-Powered Web Scraping Tools: A Comparative Overview
Let's dive into the tools that are revolutionizing web scraping with AI integration. I'll compare six different approaches, analyzing their features, costs, and real-world performance.
3.1 Jina.ai Reader for Web Scraping
Jina.ai Reader represents a significant advancement in web scraping technology. Here's what makes it stand out:
Key Features
Converts HTML to markdown format
Provides cleaned, LLM-friendly output
Cloud-based API
Easy implementation
Cost Structure
1 million free tokens on signup
$20 gets you 1 billion tokens
Cost analysis: You can scrape a job listing site 125,000 times for $20
Implementation
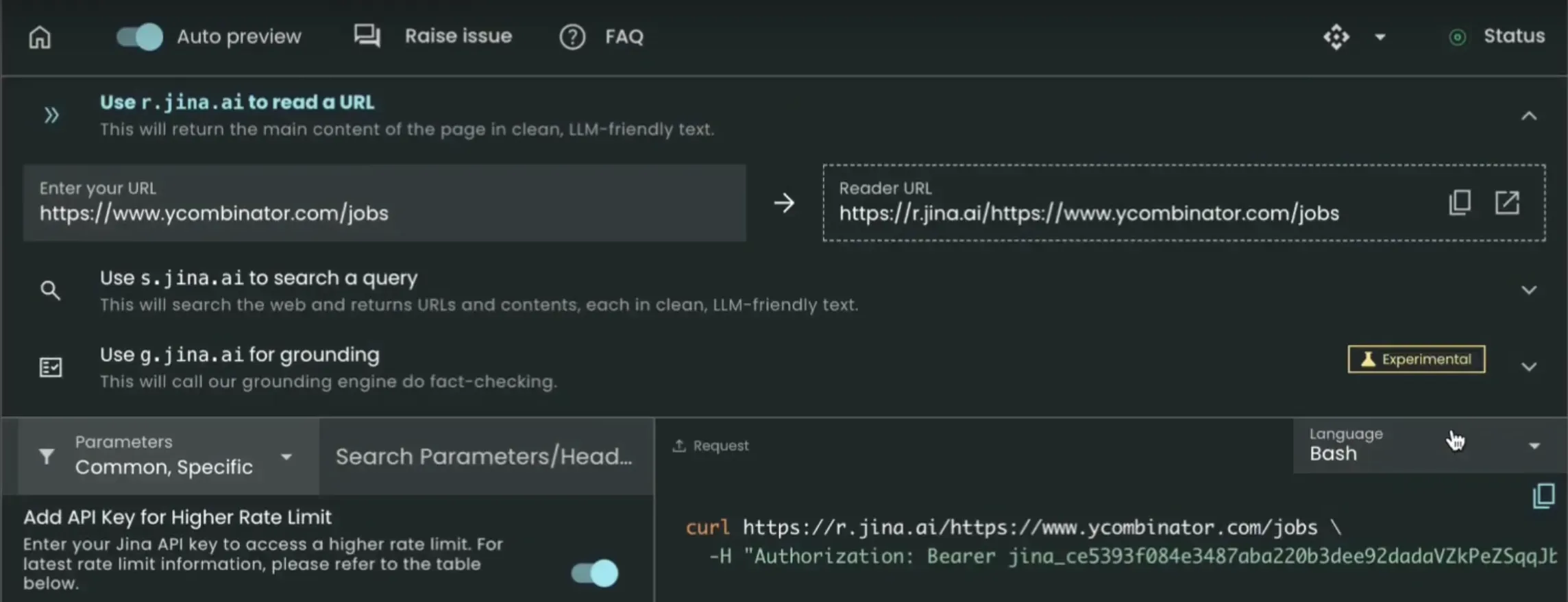
Using Jina.ai is straightforward:
Add "r.jina.ai" prefix to your target URL
Make API call
Receive markdown response
Overview of the Jina.ai playground
Token Efficiency
Let's compare the token usage:
Beautiful Soup raw HTML: ~65,000 tokens
Jina.ai markdown output: ~7,000 tokens
Result: 90% reduction in token usage
Limitations
The main challenge comes with protected websites:
Requires proxy server for sites with anti-bot measures
Example: When trying to scrape the Argentine real estate site, you'll get a 403 "Forbidden - Verifying you are human" response
Solution: Need to configure proxy settings in the tool
3.2 Firecrawl Web Scraping
Firecrawl takes a more comprehensive approach to AI-powered scraping.
Core Features
LLM-friendly output formats in Markdown or JSON
Built-in proxy handling
Extract mode for LLM-free operation
Cost Breakdown
Initial Offer: 500 free requests on signup
Monthly Subscription: Starting at $19
Per-request cost: $0.64 (at maximum usage)
Extract mode: 5x higher cost
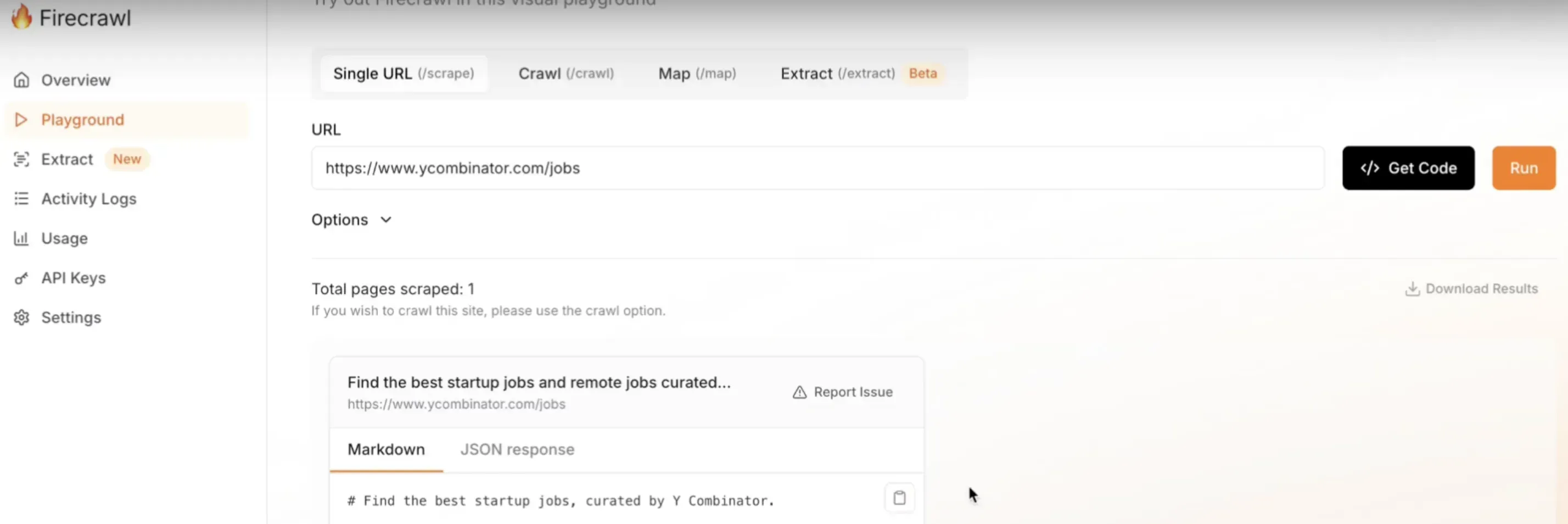
Overview of the Firecrawl playground
Extract Mode
Firecrawl's extract mode deserves special attention:
Eliminates need for separate LLM
Requires schema definition
Example schema:
1{
2"jobs":{
3"company_name":"string",
4"job_title":"string",
5"location":"string"
6}
7}
Performance Testing
I tested Firecrawl on our Y Combinator job board example:
Token usage: 6,553 (even lower than Jina.ai)
Extract mode beta testing showed limitations: Sometimes returns incomplete results. Better to use your own LLM for reliable extraction
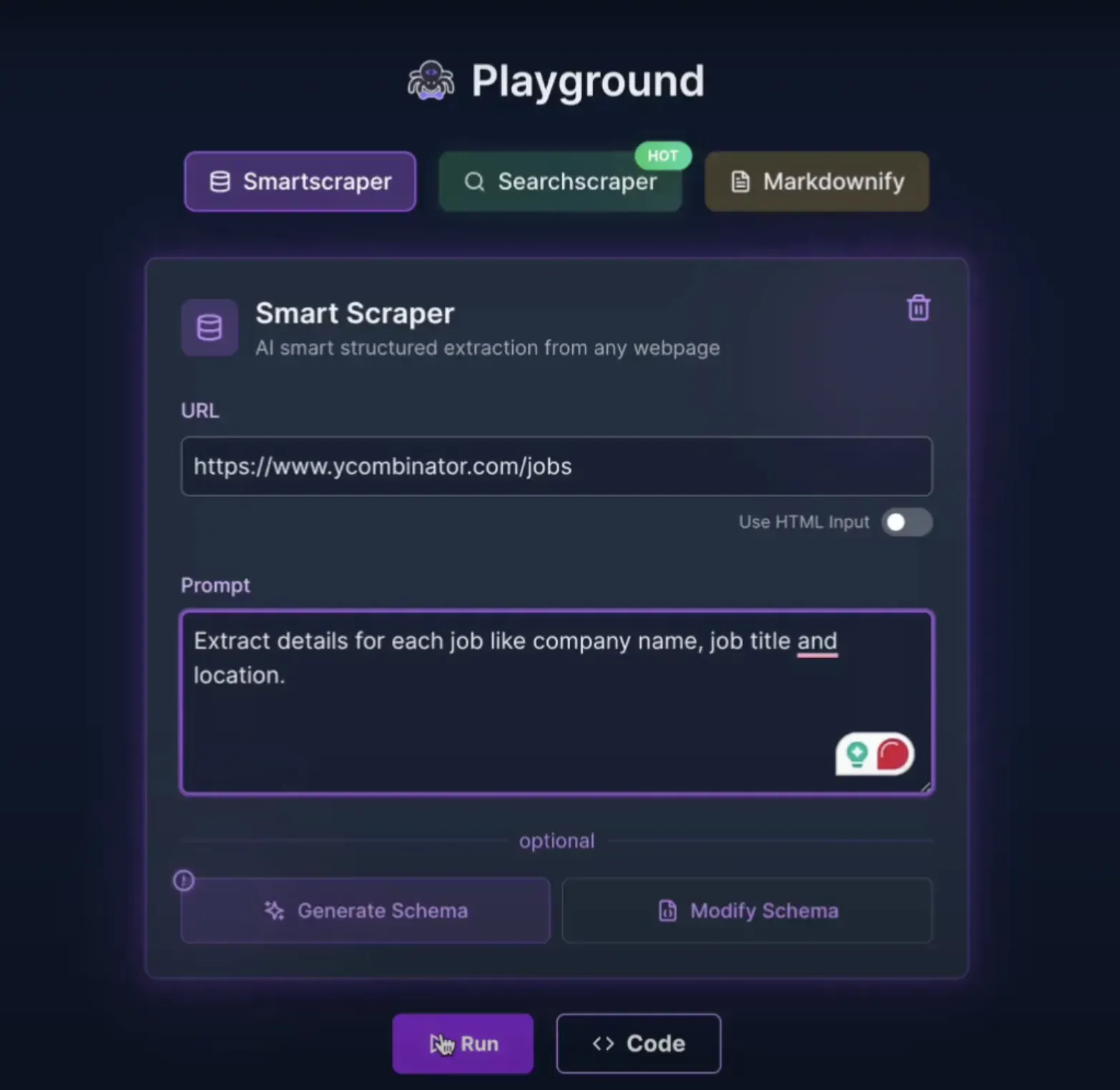
3.3 ScrapeGraph AI Review
ScrapeGraph AI offers similar capabilities to Firecrawl but with some key differences.
Features
Extraction mode
Structured output formats (Markdown/JSON)
Improved schema definition system
Natural language prompting
Pricing Structure
Free tier: 100 requests on signup
Monthly subscription: Starting at $20
Per-request cost: $0.8 (at maximum usage)
Extract mode: 5x base cost
Overview of the ScrapeGraphAI playground
Real-World Testing
I tested ScrapeGraph AI on our job board example:
Prompt: "Extract details for each job: company name, job title, location"
Results:
Successfully extracted all job listings
Accurate company names, titles, and locations
Consistent JSON structure
Better schema handling than Firecrawl's extract mode
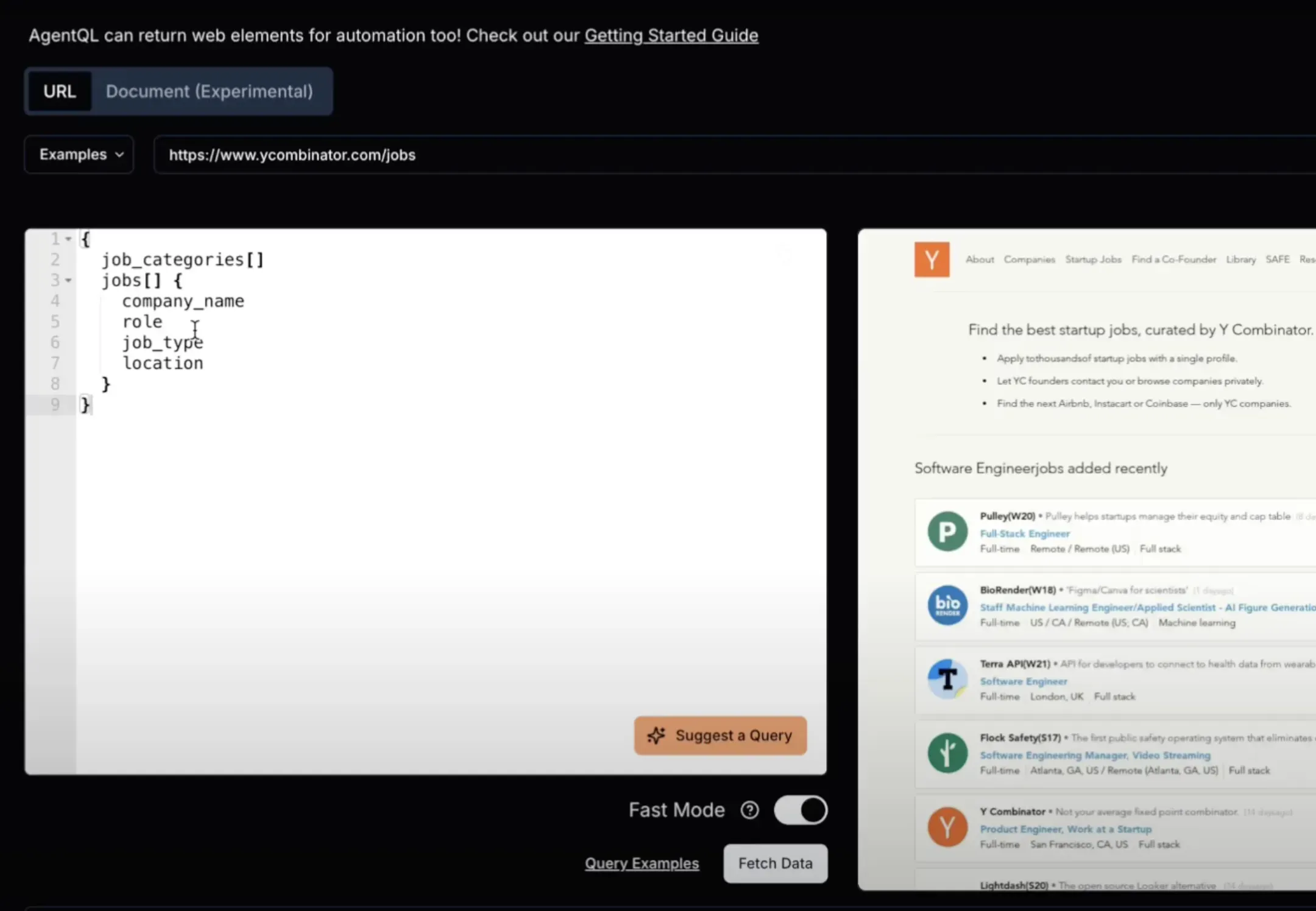
3.4 AgentQL Web Scraping Tutorial
AgentQL represents the next evolution in web scraping, bringing agentic features to the table.
Advanced Capabilities
Natural language data selection
Browser automation actions: form filling, button clicking, scrolling, navigation
Playwright integration (headless browser)
Structured data output
Cost Structure
Free tier: 300 requests for testing
Pricing model: Pay-as-you-go
Per request cost: $0.02
No monthly commitment required
Overview of the AgentQL playground
Implementation Example
Here's how to use AgentQL for form automation:
1import{AgentQL,PlaywrightBrowser}from'agentql';
2
3const config ={
4 url:'<https://example.com/contact>',
5 formQuery:`
6 Find and fill these fields:
7 - First Name
8 - Last Name
9 - Email Address
10 - Subject (select field)
11 - Comment
12 Then click 'Continue' button and 'Confirm' button
3 Break down large content into processable chunks
4 while maintaining context
5 """
6 chunks =[]
7 current_chunk =[]
8 current_size =0
9
10for line in markdown_content.split('\\\\n'):
11 line_size =len(line.split())
12
13if current_size + line_size > max_chunk_size:
14 chunks.append('\\\\n'.join(current_chunk))
15 current_chunk =[line]
16 current_size = line_size
17else:
18 current_chunk.append(line)
19 current_size += line_size
20
21if current_chunk:
22 chunks.append('\\\\n'.join(current_chunk))
23
24return chunks
5. Building an AI-Powered Scraping Dashboard
Let's dive into the practical implementation of our scraping system.
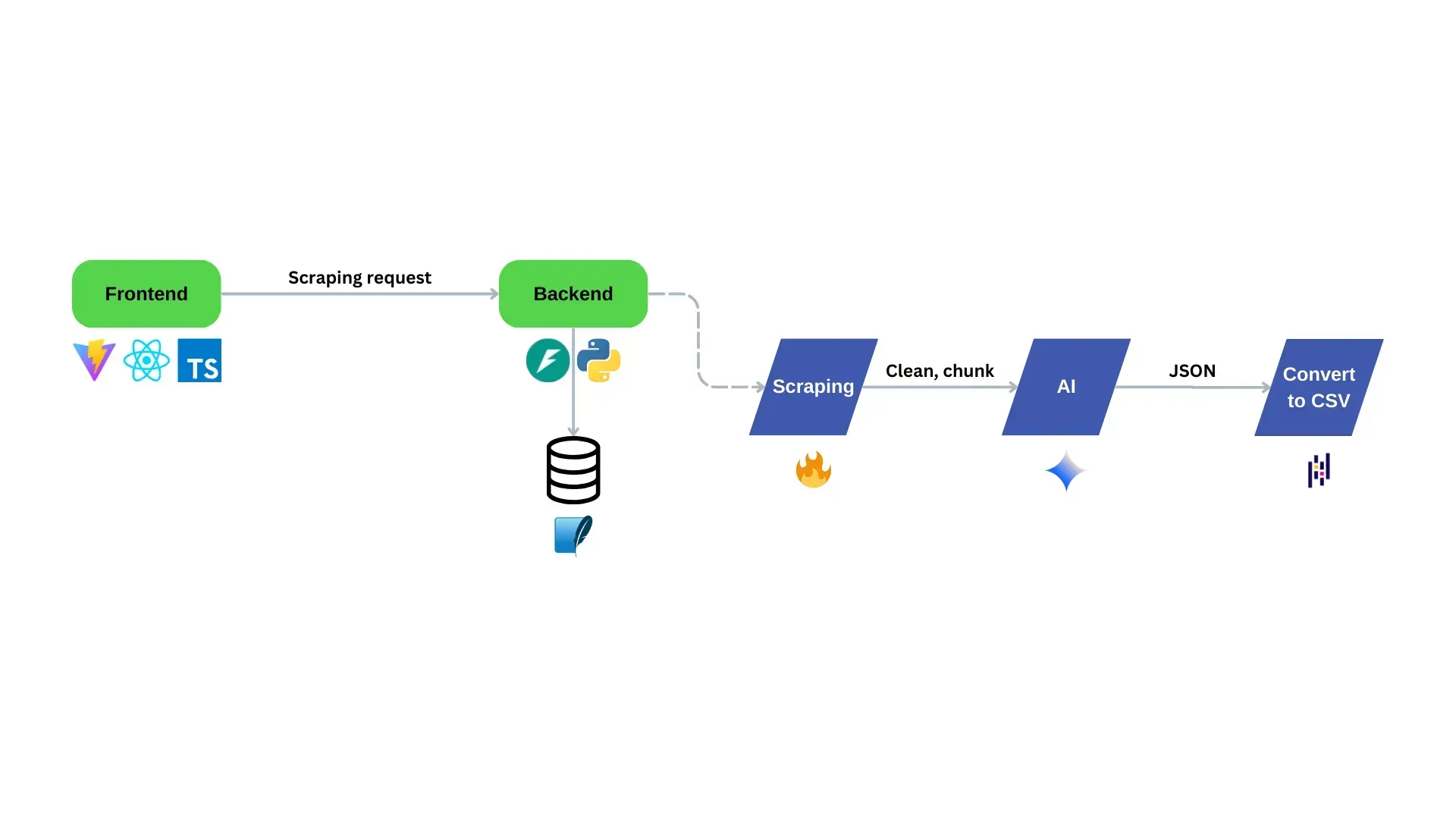
5.1 Architecture Overview
Frontend Stack
React with TypeScript and Vite
Modern UI components
Real-time status updates
Download management
Backend Components
FastAPI (Python)
SQLite database
Firecrawl integration
Gemini model processing
Data Flow
Frontend sends scraping request
Backend initiates Firecrawl job
Content cleaning and chunking
Gemini processes with JSON output
Pandas converts to CSV
Flow chart of an architecture overview of the AI scraping dashboard
5.2 Implementation Details
I walk you through the core processing function in my video above. Take a look if you’re interested.
5.3 Dashboard Features
If you’re interested in the dashboard features, I also invite you to watch the last quarter of my video where I walk you through the app.
6. Future Features and Improvements
Based on user feedback and testing, here are the planned enhancements:
6.1 Data Enrichment
The idea is to transform basic scraping into rich data insights. The scraped data can be used as input for another LLM call. This time the AI agents performs a web search for additional context. Think about a location-based data enhancement:
Crime statistics for real estate listings
Walkability scores
Infrastructure details
Neighborhood demographics
6.2 Task Management
Improve multi-user support to make sure that the server can always handle the load:
Queue system implementation
Priority handling
Server load balancing
Concurrent task limits
6.3 Export Options
Expand data delivery capabilities. The user can download the scraped data in different formats:
CSV (current)
PDF reports
Excel workbooks
JSON API responses
Custom templating options
6.4 Payment Integration
Streamline the commercial aspects by integrating Stripe:
Credit packages
Subscription options
Usage-based billing
6.5 Storage Solutions
Enhance data management by integrating cloud storage:
Google Drive sync
OneDrive compatibility
Object storage options
6.6 Custom Fields
Add flexibility to data extraction. Users can define which data they want to receive:
Dynamic schema definition
Field selection interface
Template saving
Reusable configurations
6.7 Analytics Dashboard
Implement data analysis features to represent data visually:
Trend analysis
Comparative metrics
Custom reports
7. Conclusion
The future of web scraping is here, and it's powered by AI. By combining traditional scraping techniques with modern AI capabilities, we've built a system that's:
Resilient to website changes
Cost-effective through token optimization
Scalable for various use cases
Easy to maintain and update
Key Takeaways
Traditional scraping methods are increasingly unreliable
AI-powered scraping tools provide robust alternatives
Token optimization is crucial for cost management
The right LLM selection can significantly impact performance
A well-designed dashboard makes management simple
Next Steps
Stay updated with the latest in AI scraping. Subscribe to our free newsletter for:
New tool announcements
Cost optimization strategies
Implementation tips
Case studies
Future Development
I'm planning a deep-dive series on building specific scrapers for different use cases. Let me know in the comments which specific scrapers you'd like to see built in detail.
Author's Note: This article is based on current technologies and pricing as of early 2025. Check the official documentation of each tool for the most up-to-date information.
Continuous Improvement
Execution-Focused Guides
Practical frameworks for process optimization: From workflow automation to predictive analytics. Learn how peer organizations achieve efficiency gains through ROI-focused tech adoption.