Listen to this AI-generated podcast summarizing the article content for easier digestion
Introduction
What's the most valuable resource on the internet that companies can't access? It's not cryptocurrency. It's not computing power. It's data trapped behind websites with no APIs.
Until recently, extracting this data was painfully difficult. But AI is completely changing the game of web scraping. With just one simple prompt, you can now extract data from hundreds of Amazon products, monitor competitors' prices, or analyze top-performing YouTube content.
This comprehensive ScrapeGraphAI tutorial will explore how this innovative AI web scraping tool is revolutionizing data extraction. We'll cover three powerful use cases: price monitoring for e-commerce, competitive analysis on YouTube to find winning content strategies, and scraping news articles for research and analysis.
If you've struggled with traditional web scraping methods breaking whenever websites change their structure, this guide to AI web scraping with ScrapeGraphAI will show you a more resilient, accessible approach to data extraction.
What is ScrapeGraphAI?
ScrapeGraphAI is an innovative AI web scraper developed by Marco Vinciguerra, a data science and engineering master's student from Italy. The creation story begins with a failed homework assignment about web scraping two years ago.
"I was not able to understand anything about HTML and I took a bad grade," Marco explains. "So from that moment I decided to specialize in scraping."
What Marco noticed during his learning journey was that people frequently turned to ChatGPT for help with coding scraping scripts. This sparked an idea: why not build a tool that used AI directly for web scraping?
"What I've seen from my point of view was that people use traditional methods, and if the website changes even a little, your code will break," Marco says. "Instead, if you use AI for extracting data, your script will always work."
This insight led to the development of ScrapeGraphAI, first as an open-source library created "just for fun" with friends. Later, Marco and two co-founders built a company providing an API for faster and more robust data extraction on top of the library.
The key innovation of ScrapeGraphAI is its use of Large Language Models (LLMs) to understand web page content and extract the requested data using natural language instructions. Unlike traditional web scraping that relies on rigid selectors, this AI-powered approach can adapt to website changes, making your data pipelines more resilient.
ScrapeGraphAI is available in three formats:
An open-source library for developers who want maximum control
A user-friendly API with a no-code dashboard interface
An enterprise version for more complex, multi-site scraping needs
How Does ScrapeGraphAI Work?
Traditional web scraping methods like Beautiful Soup require carefully inspecting HTML code, selecting the right elements, and writing specific code to extract your data. This process is not only time-consuming but extremely fragile - even minor website updates can break your scraper.
ScrapeGraphAI takes a completely different approach to data extraction. Instead of relying on brittle HTML selectors, it leverages the power of AI to understand web page content contextually.
The process is remarkably simple:
You provide a URL to the web page you want to scrape
You write a natural language prompt describing what data you want to extract
The AI analyzes the page and returns structured data in JSON or CSV format
Behind the scenes, ScrapeGraphAI employs multiple LLMs for different tasks:
Some models handle chunking (breaking down the web page)
Others merge results into a coherent output
The system uses a mixture of models including "Llama, Grok, Mistral mini, and Mixtral"
This architecture ensures the platform remains compliant and always available, even if individual models experience issues.
From a technical perspective, ScrapeGraphAI uses:
Superbase for authentication
AWS for internal requests and lambdas
Render for other cloud services
The entire platform runs in the cloud, making it scalable and accessible from anywhere.
What truly sets ScrapeGraphAI apart from traditional web scraping Python libraries is its ability to extract meaningful data through simple instructions rather than complex code. You can request "extract all keyboard names and prices" instead of writing dozens of lines identifying divs, classes, and element selectors.
Key Features and Use Cases
ScrapeGraphAI offers three primary features that make AI web scraping accessible to both developers and non-technical users:
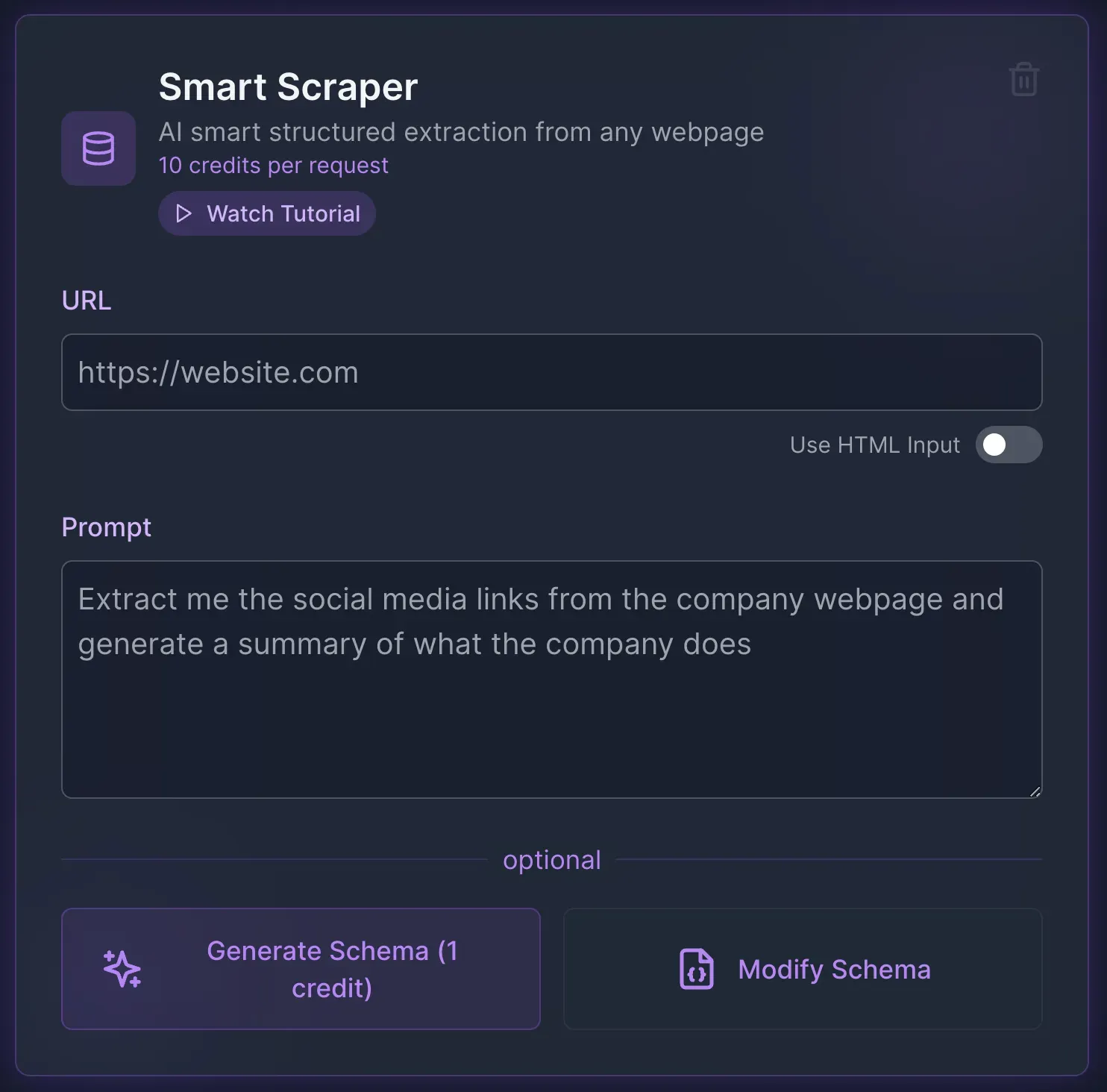
1. Smart Scraper
The Smart Scraper is the core functionality of ScrapeGraphAI. It allows you to extract specific data from any website using natural language instructions. Simply provide a URL and tell the system what data you want - product names, prices, article headlines, or virtually any visible content.
For example, you can:
Extract keyboard names and prices from Amazon
Pull video titles from YouTube
Collect article headlines and links from news sites
This feature is perfect for price monitoring, content analysis, and building datasets for training AI models.
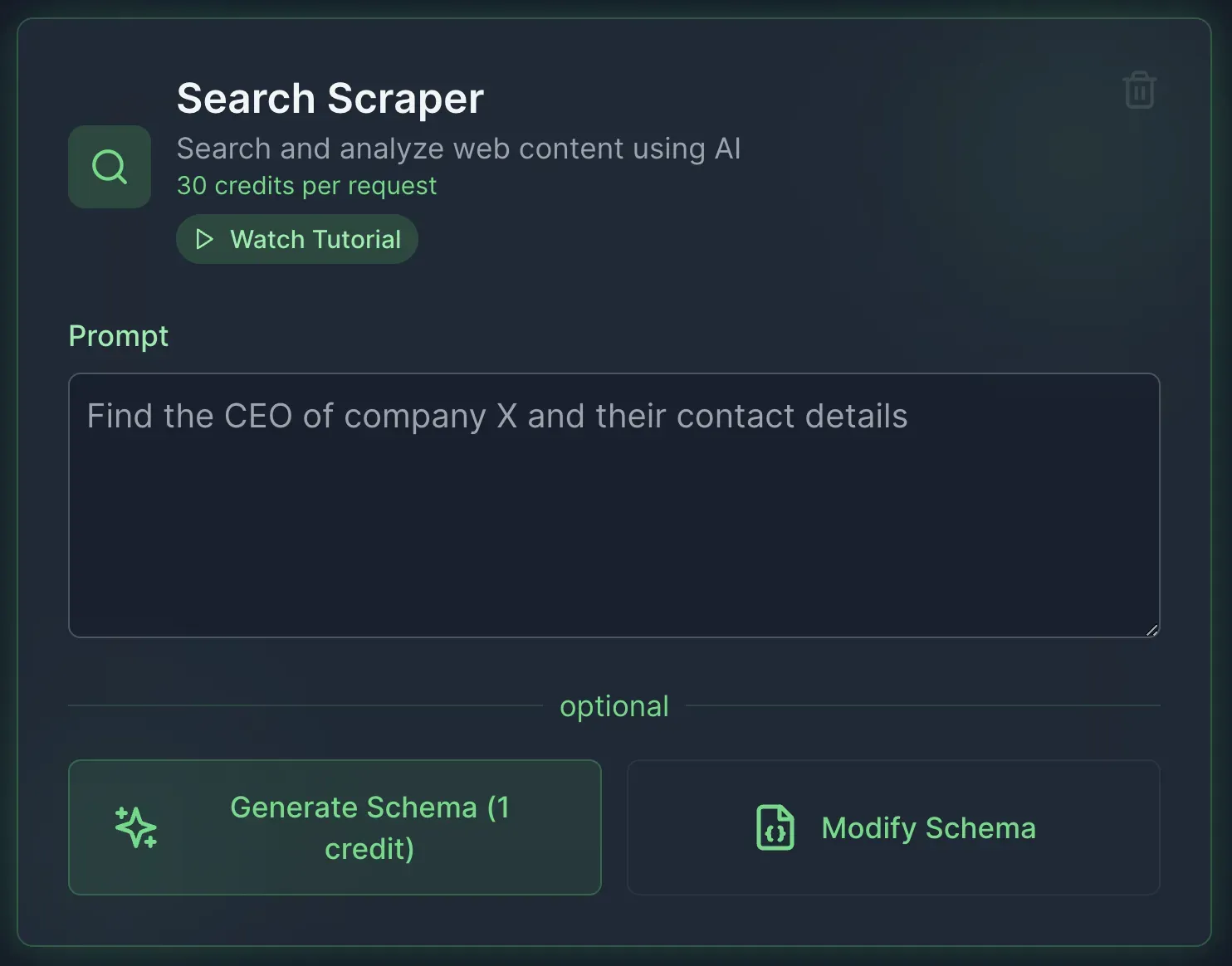
2. Search Scraper
The Search Scraper, a newer addition to ScrapeGraphAI, performs web searches based on your query and returns structured data from multiple sources. As Marco demonstrates in the tutorial, you can ask something like "Write me the last three presidents of US" and receive a structured JSON output with information collected from across the web.
Marco describes this as his "favorite endpoint right now" because of its ability to compile information from multiple sources into a single, structured format.
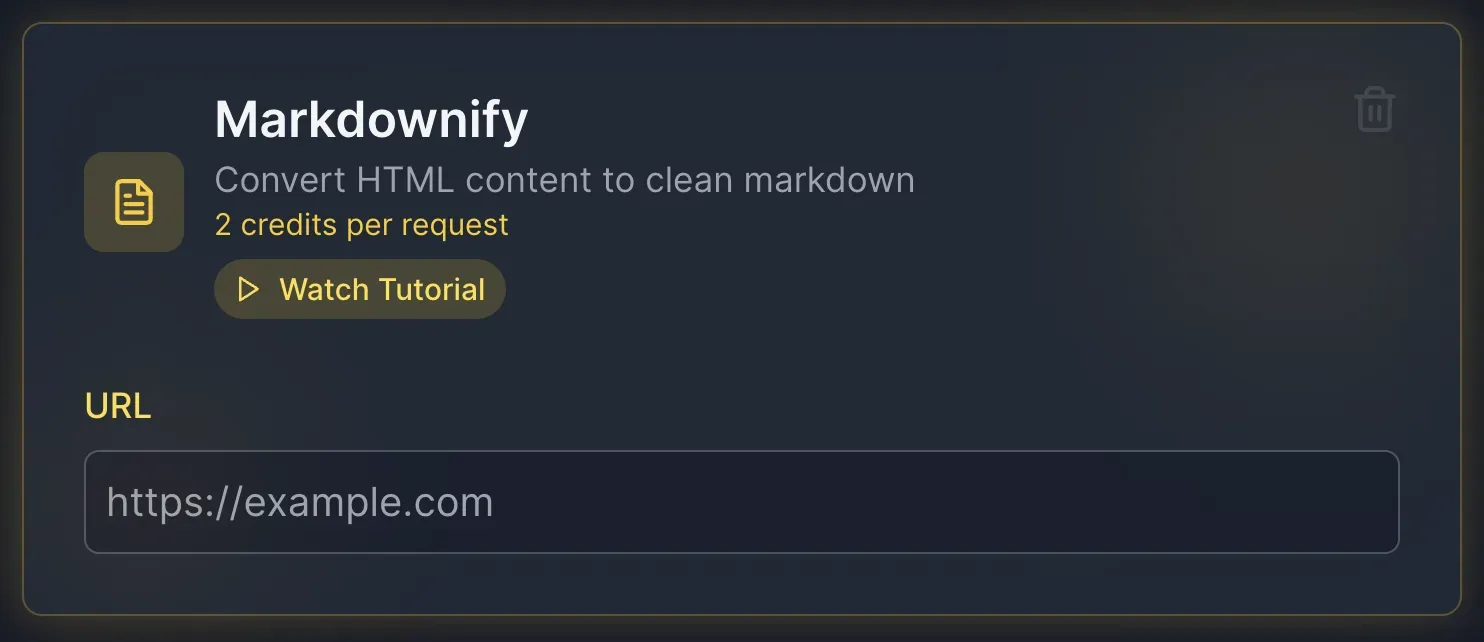
3. Markdownify
The Markdownify feature converts any web page into a clean markdown document. This is particularly useful for content creators, researchers, and anyone who needs to transform web content into a more readable, editable format.
Common Use Cases
According to Marco, the most common applications for ScrapeGraphAI include:
Social media analysis - Extracting posts, engagement metrics, and trending content
News aggregation - Collecting articles and headlines from news websites
Competitive analysis - Gathering data on competitors' products, pricing, and marketing
Some users have even created specialized datasets by scraping Korean websites for video game information, showing the flexibility of the platform for niche applications.
For businesses, these capabilities unlock valuable competitive intelligence and market insights that would be difficult or impossible to gather manually. For developers and data scientists, ScrapeGraphAI provides easy access to web data for training models, building applications, or automating workflows
ScrapeGraphAI in Action: Tutorials and Examples
Let's explore how to use ScrapeGraphAI through practical examples. This web scraping tutorial will cover both the dashboard interface and programmatic API access.
Using the Dashboard (No-Code Solution)
The ScrapeGraphAI dashboard provides a user-friendly interface for those who prefer a no-code approach to web scraping.
Navigate to the ScrapeGraphAI dashboard
Enter the URL you want to scrape
Type your prompt (e.g., "Extract all the keyboard names and prices")
Click "Run"
The system will process your request and display the extracted data in structured JSON format. You can then download the results as JSON or CSV files for further analysis.
The dashboard also provides a "Job Status" section where you can view all your recent scraping jobs, filter results, and download data from previous runs.
Using the API (For Developers)
For developers who want to integrate ScrapeGraphAI into their applications or scripts, the platform offers SDKs for Python, JavaScript, and cURL.
Here's a simple example of using the Python SDK to scrape Amazon product data:
1# Import the necessary packages
2from scrapegraph_py import Client
3from scrapegraph_py.logger import sgai_logger
4
5# Setup logging to see what's happening
6sgai_logger.set_logging(level="INFO")
7
8# Initialize the client with your API key
9client = Client(api_key="your_api_key_here")
10
11# Define the request - URL and what you want to extract
9# Initialize the scraper with custom configuration
10scraper = SmartScraperGraph(
11 prompt="Give me all the news",
12 source="<https://wired.com>",
13 config={
14"llm":{
15"api_key": os.getenv("OPENAI_API_KEY"),
16"model":"openai/gpt-4o-mini",
17}
18}
19)
20
21# Run the scraper and print results
22result = scraper.run()
23print(result)
This approach gives you more control over the scraping process, including the ability to select which LLM to use for data extraction.
Example: E-commerce Price Monitoring
One of the most common use cases for ScrapeGraphAI is price monitoring for e-commerce. By setting up regular scraping jobs for competitor websites, businesses can track price changes, promotional activities, and product availability.
For example, you could set up a daily job to scrape Amazon for keyboard prices in your category:
This script would collect pricing data daily, allowing you to track changes over time and adjust your own pricing strategy accordingly.
Example: YouTube Competitive Analysis
For content creators, understanding what titles and topics perform well is crucial. ScrapeGraphAI can help with competitive analysis by extracting video details from YouTube:
1from scrapegraph_py import Client
2
3# Initialize client
4client = Client(api_key="your_api_key_here")
5
6# Extract video information from a YouTube channel or search
9 prompt="Extract video titles, view counts, publish dates, and channel names for all videos about AI web scraping"
10)
11
12# Process results to identify patterns in high-performing content
13print(response)
14client.close()
This data could be analyzed to identify patterns in successful content, helping you optimize your own video titles and topics.
Example: News Article Scraping
Researchers and analysts often need to collect news articles on specific topics. Here's how you might use ScrapeGraphAI for news data extraction:
1from scrapegraph_ai import SmartScraper
2
3# Initialize the scraper
4scraper = SmartScraper(
5 prompt="Extract all news article titles, publication dates, authors, and summary text",
6 source="<https://wired.com>",
7 config={
8"llm":{
9"api_key": os.getenv("OPENAI_API_KEY"),
10"model":"openai/gpt-4o-mini"
11}
12}
13)
14
15# Run the scraper and print results
16result = scraper.run()
17print(result)
This approach allows you to collect news content systematically for research, sentiment analysis, or trend identification.
Addressing Limitations and Challenges
While ScrapeGraphAI offers powerful capabilities for AI web scraping, it's important to understand its limitations and how to address common challenges in web scraping.
Anti-Bot Measures and JavaScript-Heavy Sites
Many websites implement measures to detect and block scraping activities. Marco explains the differences between the open-source library and the paid API service in handling these challenges:
"We don't actually support proxy rotation, anti-bot and anti-Cloudflare in the open-source codebase because it's very difficult to implement. You have to add a lot of extra paid services," Marco explains.
For the paid API version, ScrapeGraphAI takes a different approach: "Instead of using Playwright directly, we use an external service that handles these kinds of problems like JavaScript rendering and anti-bot policies."
This means:
Open-source library users need to implement their own solutions for proxy rotation, anti-bot bypassing, and handling JavaScript-heavy sites.
API users benefit from these features being built into the service, making it easier to scrape more complex or protected websites.
For developers not experienced with coding but who need to extract data from protected sites, the API version offers a significant advantage, as these complexities are handled behind the scenes.
Legal and Ethical Considerations
While not explicitly addressed in the video, it's important to note that web scraping exists in a legal gray area. When using tools like ScrapeGraphAI, consider:
Respecting robots.txt files and website terms of service
Not overloading websites with too many requests
Using data ethically and in compliance with applicable laws
Being mindful of personal information and privacy concerns
Enterprise Solutions for Complex Needs
For more sophisticated scraping needs, particularly those involving multiple interlinked websites, ScrapeGraphAI offers an Enterprise version.
"Enterprise version is a platform where you can scrape not just one website but more websites in a crawl way," Marco explains. "If you have one link inside the website with more outlinks, with our product you will extract information from like 50 websites directly inside that link."
This capability is particularly valuable for comprehensive research tasks such as those required for mergers and acquisitions (M&A), where gathering as much information as possible about a company is essential.
Integration with Automation Platforms
For many businesses, the real value of web scraping comes from integrating extracted data into existing workflows and automation systems. ScrapeGraphAI facilitates this through integration with popular automation platforms.
Current Integration Options
According to Marco, ScrapeGraphAI can be used with automation platforms like Make.com and n8n through API calls.
"A lot of people use automation platforms like Make.com, n8n... Make.com is really popular right now. In this case, you can just use the API," Marco explains. "You can just add an API call in Make.com and use the official API and just add this to your automation workflow."
This approach allows businesses to:
Automatically scrape competitor pricing data and update their own prices
Monitor news sites and post updates to social media when relevant articles appear
Track YouTube metrics and generate performance reports
And much more, limited only by creativity and business needs
Upcoming Official Integrations
Marco also shared plans for expanding integration options: "Regarding this kind of automation platform, we are trying to be in more as possible. So we have like the integration with Langflow. We are releasing our first template for Langflow in the next days."
Looking further ahead, he noted: "In the future we will also add Zapier, for example, or n8n."
These official integrations will make it even easier to incorporate ScrapeGraphAI into existing business processes, reducing the technical expertise required to leverage web scraping for business intelligence.
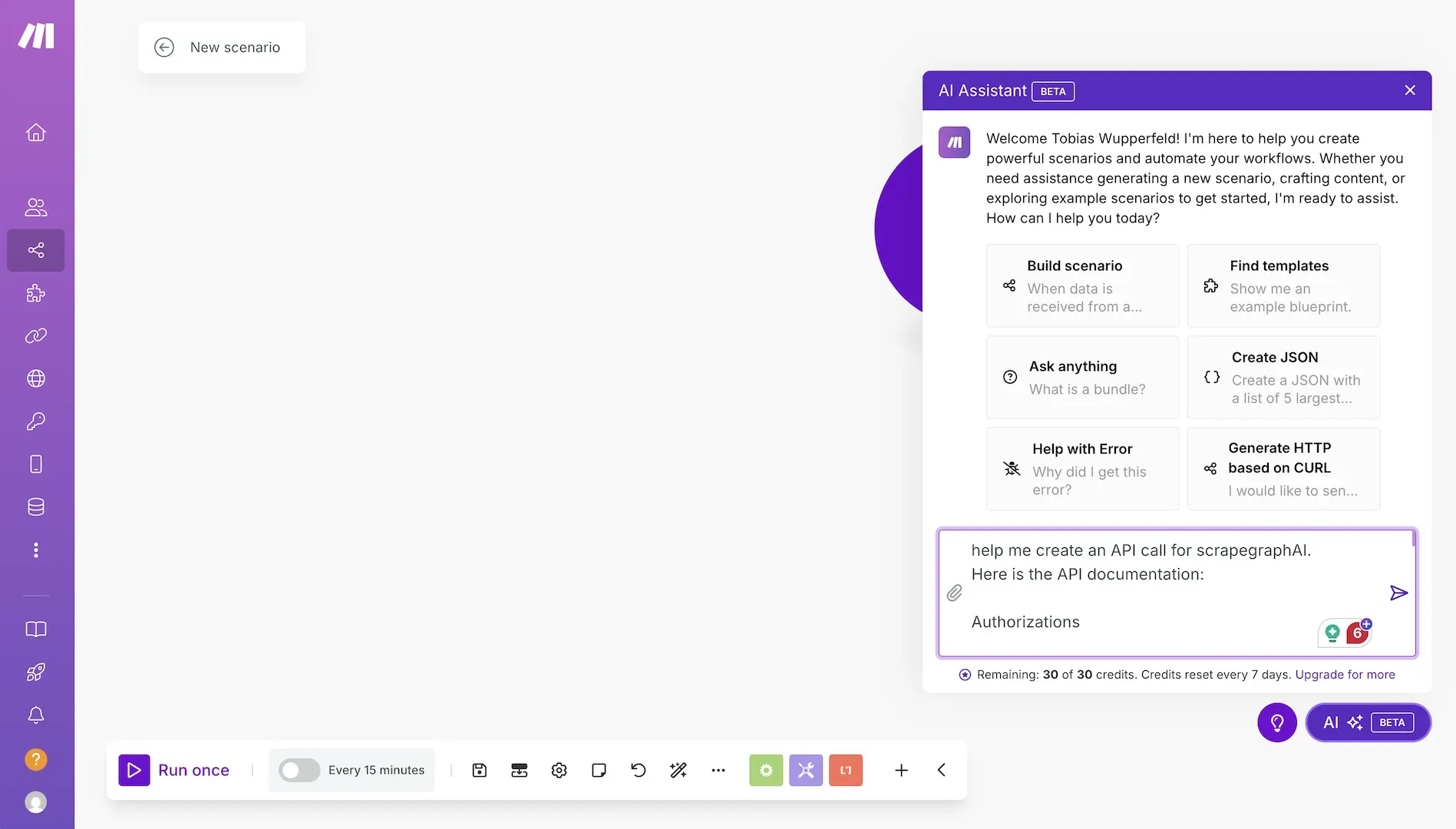
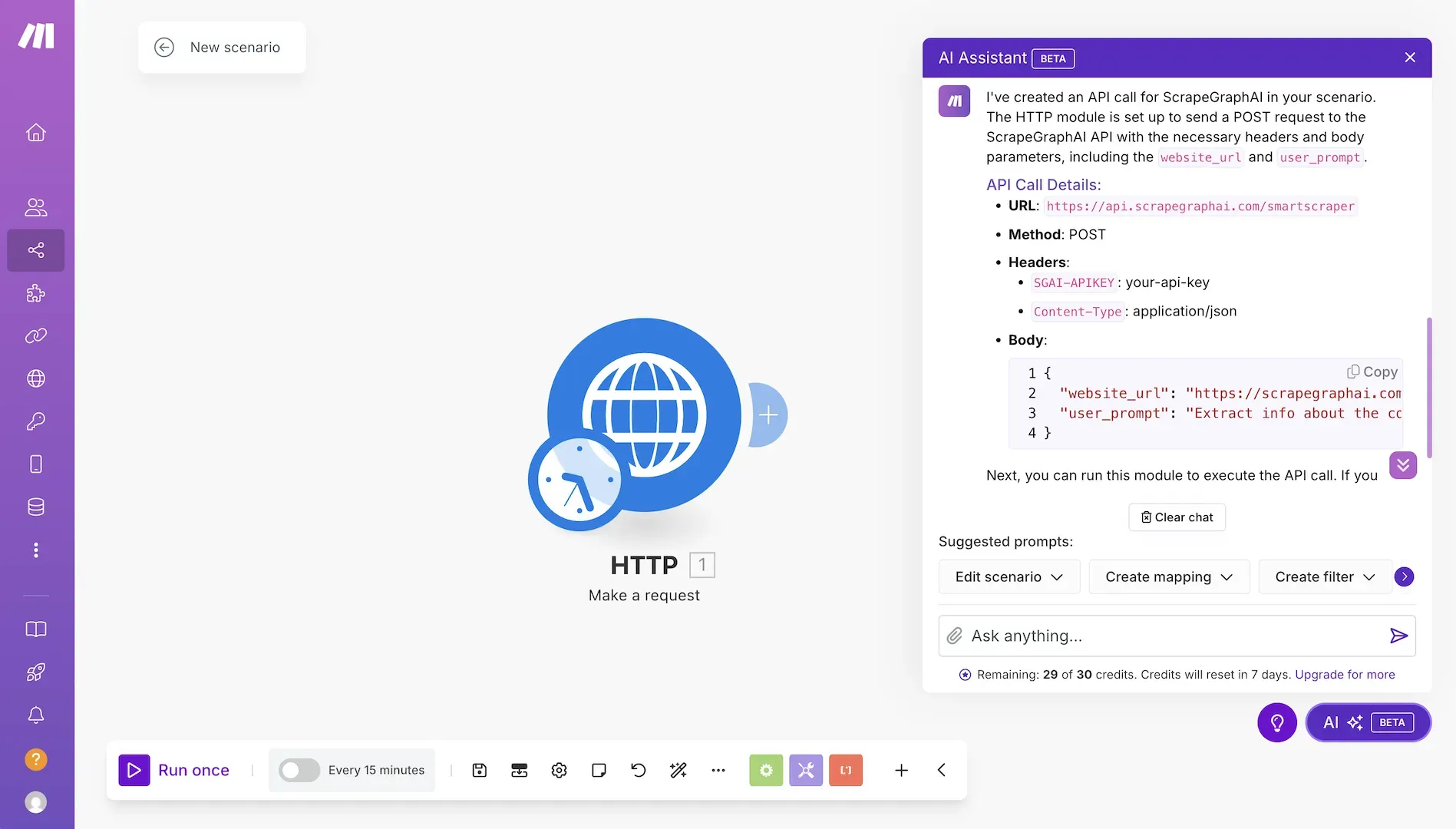
Example: Integrating with Make.com
While the official integrations are still in development, users can already connect ScrapeGraphAI to Make.com using the API:
The easiest way to do this is to prompt the make assistant to create the API call for you. Just copy the relevant parts of the ScrapeGraphAI API documentation and paste it into the prompt window.
After that you receive the ready-made node and you can add your API keys, website_url and prompt for the extraction.
This integration could be used to create powerful workflows, such as:
Scraping competitor prices, comparing them to your own, and sending alerts when your prices are not competitive
Monitoring review sites for mentions of your brand and routing negative reviews to your customer service team
Collecting industry news and summarizing it into a daily digest email for your team
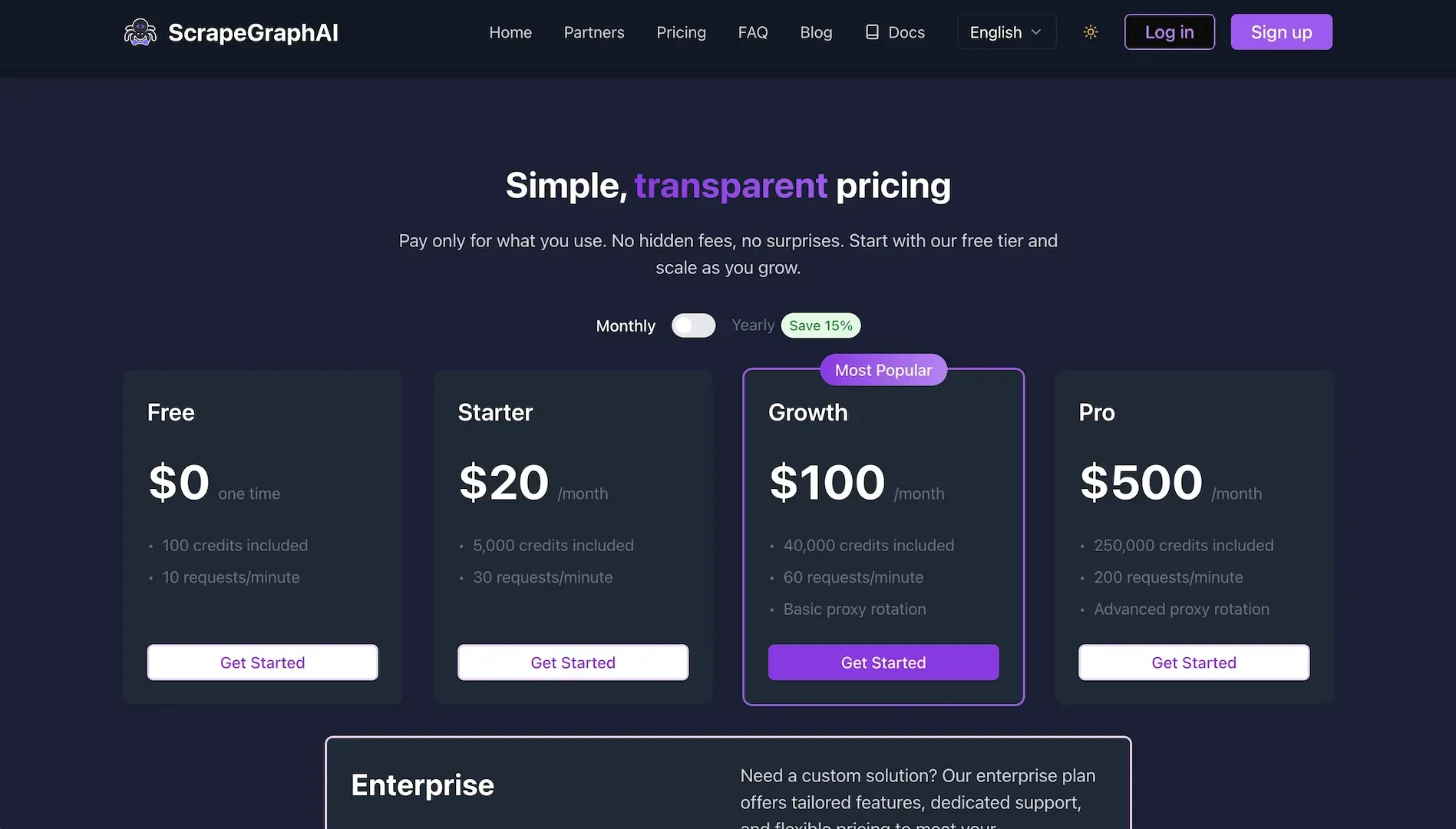
Pricing and Rate Limits
Understanding the pricing structure and rate limits is essential for planning how to use ScrapeGraphAI effectively in your projects or business.
API Rate Limits
Marco explains that rate limits vary based on your subscription plan:
"It's up to the billing account. For example, with the $20 account, you have 30 requests per minute. With the Growth plan, you have 60. And with the Pro, 200 requests per minute."
These limits determine how many scraping operations you can perform simultaneously, which is important for larger-scale data collection needs.
Open-Source Library Limitations
For those using the open-source library with their own LLM, different considerations apply:
"If you use the library and you set up your own LLM, for example, you don't have these limits," Marco explains. "The limitations are up to the LLM provider, so it's not up to us... it depends by the billing account that you have inside your LLM provider."
This means that users who self-host LLMs like Mistral or Llama could potentially have unlimited scraping capacity, constrained only by their computing resources and the performance of their chosen model.
Scaling Considerations
For large-scale scraping needs, Marco suggests that hosting your own LLM could be a viable approach:
"In case you want to really scale it, you could host your own LLM like, I don't know, Mistral or Llama."
This approach provides maximum flexibility and control, though it requires more technical expertise and infrastructure management.
Pricing as of March 2025
The Future of AI Web Scraping with ScrapeGraphAI
As LLMs continue to advance, the capabilities and applications of AI web scraping tools like ScrapeGraphAI are expected to grow significantly.
Vision for ScrapeGraphAI
Marco sees ScrapeGraphAI evolving beyond simple data extraction: "I see my company in the future not just for scraping but... as a tool for gaining knowledge for agents and reasoning models."
He explains this vision further: "Because even if you have AGI, you will not have for sure all the knowledge about the world. So you will need an extra tool for extracting the data, for gaining the knowledge to the agent."
This perspective positions ScrapeGraphAI as a complementary technology to the emerging landscape of AI agents and reasoning systems - a tool that helps AI systems access and interpret the vast amounts of unstructured data on the web.
Comparison with Big Tech Solutions
When asked about tools like OpenAI's Operator, which includes web browsing capabilities, Marco points out an important distinction:
"For my experience, even with Claude if I remember correctly, these kind of big companies, for legal problems, are not allowed to scrape each website they want. So they have a kind of limitation about that."
He speculates that large companies like OpenAI will likely pursue direct API partnerships rather than web scraping: "I think that in the future, OpenAI will directly create a kind of direct API with the providers. So instead of going to Booking.com, it will have a kind of APIs for directly connecting to booking appointment or something like that."
This creates an opportunity for tools like ScrapeGraphAI that don't face the same legal constraints: "We don't have that kind of legal limitations."
Performance Advantages
I also want to note performance advantages of specialized scraping tools: "Regarding the speed, I've seen some of the demos of the Operator, and also tried Claude Computer Use myself, and they are pretty slow actually. I mean, they're taking screenshots and then processing the next step, then they click something, and then you need to wait again."
By comparison, purpose-built web scraping tools like ScrapeGraphAI can offer more efficient and targeted data extraction.
Integration with AI Frameworks
Marco mentioned that ScrapeGraphAI is already being integrated with popular AI frameworks:
"We have like integrations with LlamaIndex, with LangChain, and CrewAI."
These integrations position ScrapeGraphAI as a component in the broader AI ecosystem, allowing it to serve as a data source for increasingly sophisticated AI applications.
Conclusion
AI web scraping is transforming how businesses and developers access the vast troves of data locked behind websites without APIs. ScrapeGraphAI represents a significant evolution in this field, making data extraction more accessible, reliable, and adaptable.
As Marco puts it: "I think that ScrapeGraph will make data accessible to everyone, not just for engineers or developers."
The key advantages of ScrapeGraphAI include:
Resilience to website changes - Unlike traditional scrapers that break when websites update their structure, AI-powered scraping adapts to changes
Accessibility for non-developers - Natural language prompts replace complex HTML inspection and selector-based code
Flexibility across use cases - From e-commerce price monitoring to competitive analysis and news aggregation
Integration capabilities - Works with popular automation platforms and AI frameworks
Scalability options - From simple API calls to enterprise-level multi-site crawling
For businesses seeking competitive intelligence, developers building data-driven applications, or researchers gathering information at scale, ScrapeGraphAI offers a powerful alternative to traditional web scraping approaches.
The future of web scraping lies in intelligent, adaptive systems that understand context rather than rigid selectors. As AI continues to advance, tools like ScrapeGraphAI will likely become essential components of data pipelines, business intelligence systems, and AI agents seeking to understand the world through web data.
This article was based on an interview with Marco Vinciguerra, founder of ScrapeGraphAI, exploring the capabilities and applications of this innovative AI web scraping tool.
Continuous Improvement
Execution-Focused Guides
Practical frameworks for process optimization: From workflow automation to predictive analytics. Learn how peer organizations achieve efficiency gains through ROI-focused tech adoption.