
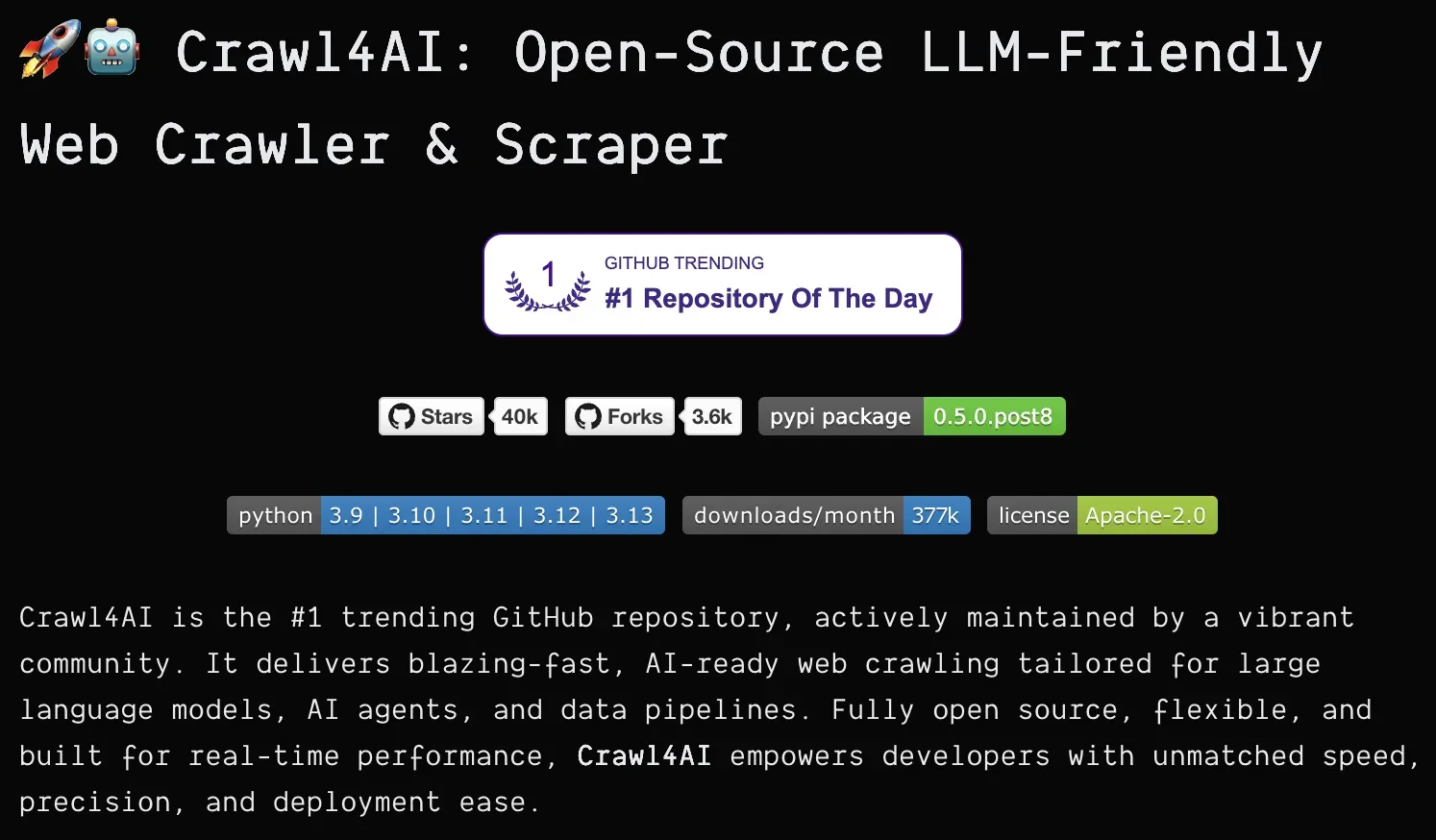
Crawl4AI
Crawl4AI is a powerful Python library for web data extraction built specifically to work with Large Language Models. It transforms web content into structured data formats that are ideal for AI processing. The tool respects website crawling rules and offers various crawling strategies from simple page extraction to complex graph-based website traversal. As an open-source project with over 40,000 GitHub stars, it represents a community-driven approach to ethical web data acquisition.
Quick Info
Screenshots
Key Features
LLM-Friendly Output
Formats extracted data specifically for optimal processing by large language models.
Smart Crawling Strategies
Uses various algorithms including graph search to efficiently navigate website structures.
Robots.txt Compliance
Automatically respects website crawling rules to ensure ethical data collection.
Content Extraction
Pulls specific elements from web pages based on custom schemas or natural language queries.
Multiple Output Formats
Supports various data export formats for integration with different systems.
Version Control
Follows standard Python versioning with clear development stages from alpha to stable releases.
Use Cases
AI Training Data Collection
Gather structured web data to train or fine-tune large language models with real-world information.
Content Aggregation
Build news aggregators, price comparison tools, or research platforms that compile information from multiple sources.
Market Research
Extract competitive intelligence, pricing data, or product information from industry websites.
Academic Research
Collect and analyze online content for scientific studies and publications.
SEO Analysis
Gather data about websites for search engine optimization purposes.
Pricing
Free and open-source (Apache 2.0 license with attribution requirement)
Setup Steps
- Install using pip: pip install -U crawl4ai
- Import the library in your Python code
- Configure crawling parameters and target URLs
- Define extraction schema if needed
- Execute crawl operations
- Process and use the extracted data