
Jina.ai Reader is an open-source tool that transforms messy web content into clean, structured text perfect for large language models (LLMs). It removes ads, navigation bars, scripts, and other clutter that typically makes web scraping difficult. The tool works by rendering webpage content in a browser and extracting only the main content. It supports multiple languages, handles PDFs natively, and processes most URLs within seconds. Reader is designed to solve the common challenge of feeding high-quality web data into AI systems without the complexity of traditional scraping methods.
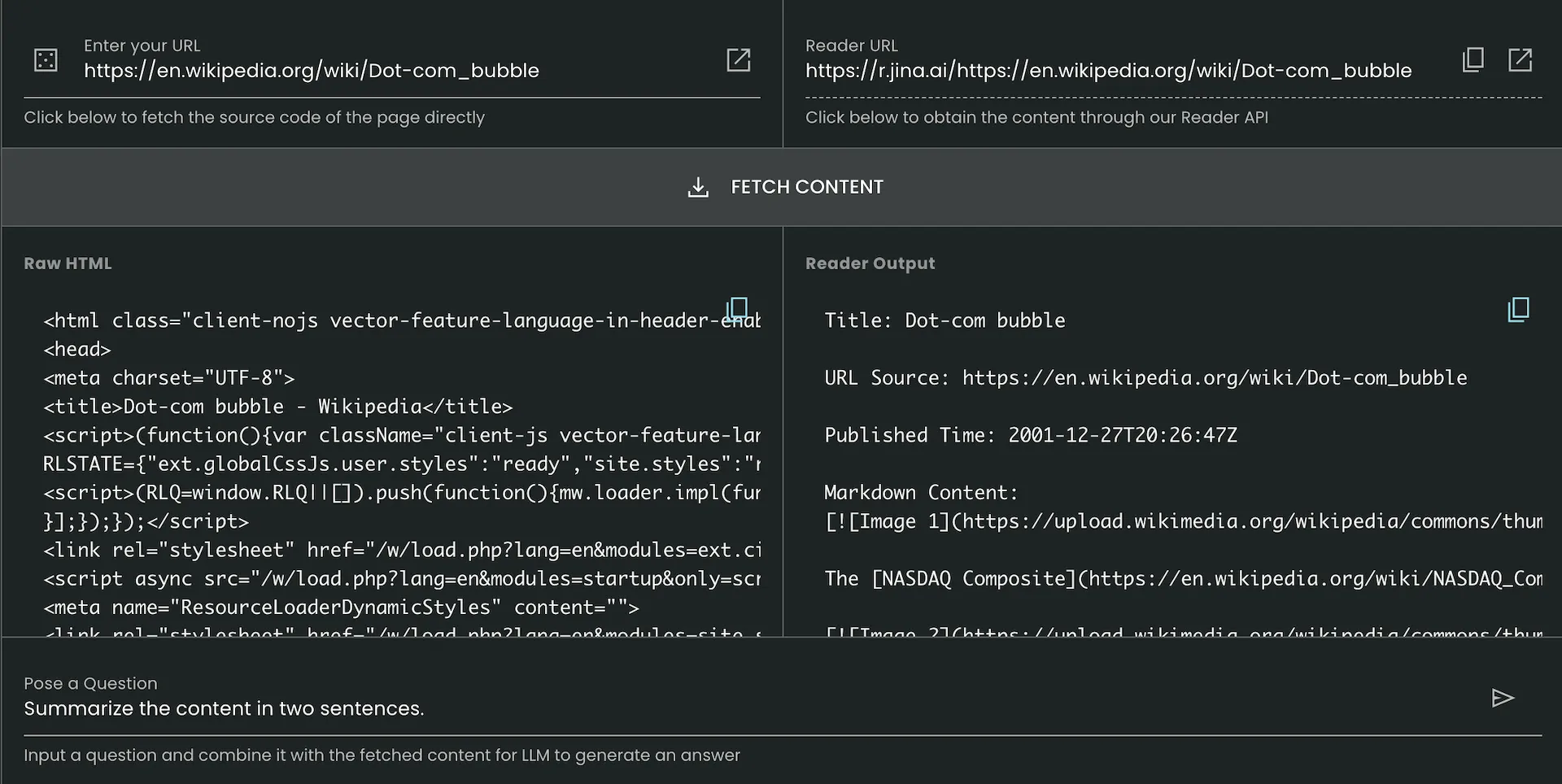

Access the API by simply prefixing any URL with "https://r.jina.ai/". No authentication or complex setup needed.
Automatically identifies and extracts the main content from webpages, removing ads, navigation, and other irrelevant elements.
Natively extracts text from PDF files including academic papers from sources like arXiv.
Automatically caches content for 5 minutes, reducing load times for repeat requests to the same URL.
Captions images found on webpages and adds alt tags, allowing downstream LLMs to interact with visual content.
Handles up to 4000 concurrent requests with automatic scaling based on traffic, making it suitable for production use.
Quickly gather and analyze content from multiple sources without dealing with web scraping complexities.
Extract and process text from PDF files including research papers, reports, and documentation.
Provide real-world, up-to-date information to AI agents, allowing them to access and process web content reliably.
Extract and summarize key points from articles, blogs, and news sources for research or content creation.
Feed clean, structured web content into language models to improve response quality and reduce hallucinations.
Completely free with no API key required. No usage limits except reasonable rate limits.